The imported file will be used as the juxtalinear left column (Source Text)
The user have two options here:
Find a USFM format file on Door43, download it, and select it from the dialog
Use a local USFM or JSON format file. For JSON format files only, the user must rename the file with the abbreviated book name (e.g., MRK.json or mrk.json)
Both individual and multiple books can be imported
Note that it will be possible to create a juxtalinear only for the books available in the uploaded Source Text file
Select the created Juxta project from the Projects page
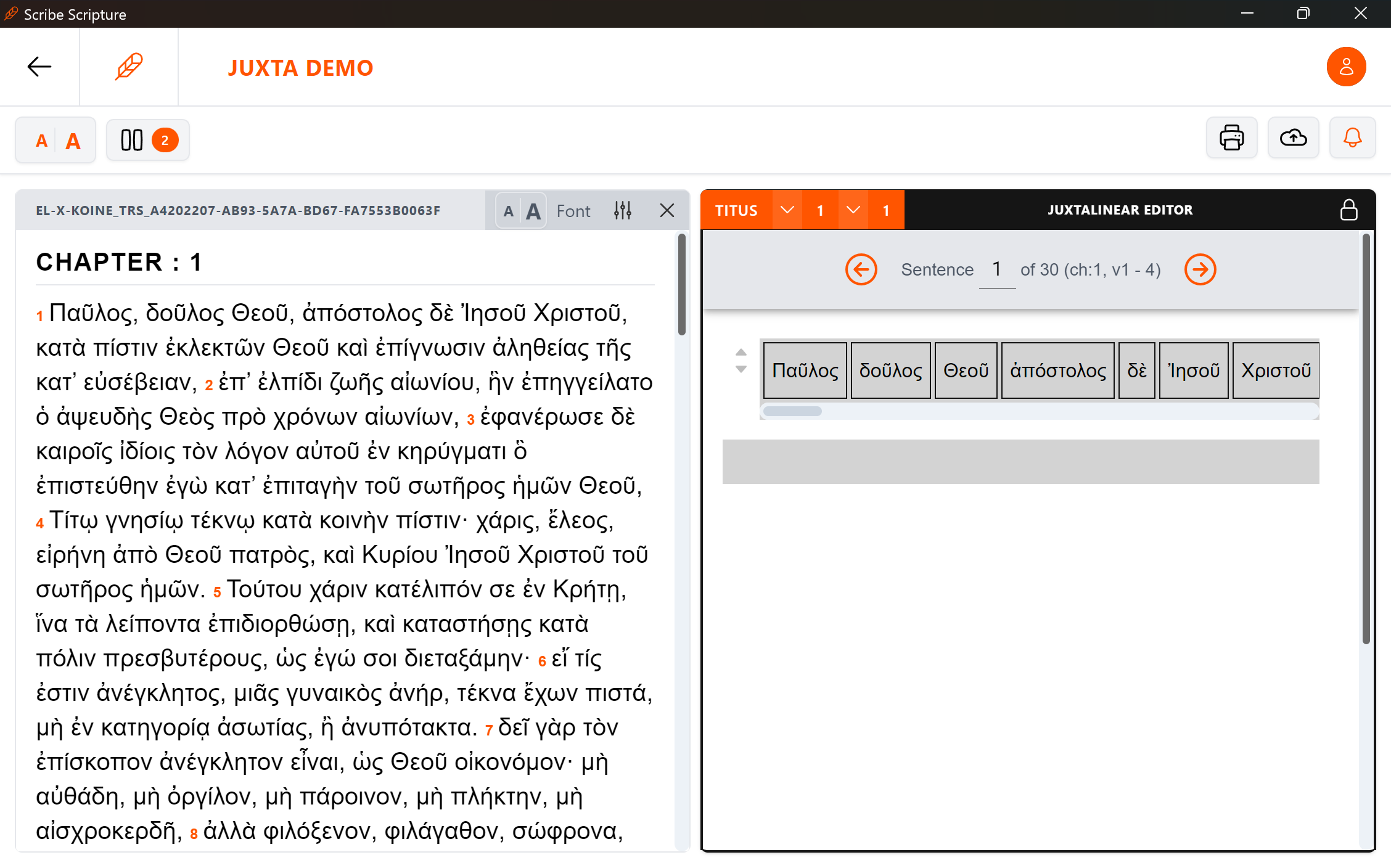
When starting a juxtalinear, the user will see a Source Text sentence (a few verses) displayed on a single line
From here, working on a juxtalinear consists of:
Splitting the Source Text sentence into small grammatically-meaningful chunks (containing words that belong together grammatically)
Double-click on a word to split the sentence on that specific word
Double-click on a chunk first word to merge it back with the previous chunk
Rearranging the Source Text to approach the natural Target Language word order
Hold click on a word
Drag the word within the line, or between lines
Release the click
Adding a hyper-literal translation for each chunk
Add a translation with a double-click on a text field or with a click on Edit
Type a translation
Exit editing with a click outside the text field or with a click on Check
Note that these three steps can be done in another order, the user may want to start rearranging before splitting, or split and rearrange the whole sentence before starting translation for example
In addition, the user may want to use those two juxtalinear conventions to ease translators understanding:
Each Source Text word should be translated into only one Target Language word. When two Target Language words are needed, link them with a dash
Use italics for needed Target Language words that are not in the Source Text. This is done by putting the word between asterisks
In general, note that the Target Text translation does not need to be elegant, it just needs to convey the sense of the words in each Source Text chunk